 域名不卖,勿扰!
域名不卖,勿扰! 音频常识
声音是指声波作用于听觉器官所引起的一种主观感觉。
人耳可听范围是20Hz~20KHz。(小于20Hz为次声波,大于20KHz为超声波。)
语音范围300~3400Hz
音频基础
声学上可用响度(音强)、音调、音色和音长等来描述

物理学上,声音是一种机械波,是机械振动在弹性介质中的传播。声波是一种纵波,震动方向和传播方向平行。Sound waves are Longitudinal waves
声音可以用以下三个基本物理量来描述。

尽管这两种关于声音的描述有所不同,但它们之间有对应的关系,物理学上声音的三个基本参量:频率、振幅和波形,对应人的主观感觉就是音调、响度和音色。
音调是由声音频率的高低决定的。频率高则音调高,反之则低。
响度和声波振动的幅度有关。声音源的振幅越大响度也越大。
音色和材料有关。不同发声体由于材料、结构的不同,发出声音的音色也就不同。(不同材料中声音的传播速度不同)
音频的数字化
现实中的声音在时间上是连续的波形,是模拟量。而我们日常听到的用手机或者电脑播放的是离散的数字音频。
那么,计算机是如何理解、存储和处理音频的呢?
声音的采集,需要经过 ADC 处理转为数字信号,最常见是 ADC 转化方式是脉冲编码调制PCM (Plus Code Modulation)。PCM 编码需要经过采样、量化、编码3个步骤处理。
(1)采样,把时间转换成离散值。音频数字化需要首先按照一定的时间间隔将连续变化的模拟信号进行采样。这个时间间隔称为采样周期 T,1/T 称为采样频率,采样频率越高,单位时间内截取的声波样本越多,得到的声音数据就越多,获得的音频波形才越接近模拟的波形,也就是数字化的音频失真越小,当然,需要的存储空间也就越大。
如下图,上半部分表示原始音频的波形;下半部分表示录制后的波形;黑点表示采样点。

上下波形之所以不吻合,是因为采样点不够多,或是采样频率不够高。
根据Nyquist采样定律,采样率不应低于模拟信号频率的2倍。也就是说至少半周期采样一次,才能不失真。由于人耳的可接受声音频率范围在20Hz~20KHz,所以采样率应该在40KHz之上。某些人能听到略高于20KHz的声音,留下一些缓存空间,采集率定为44.1KHz,这是最为常见的采样率。
采样频率:每秒钟采样的点的个数。常用的采样频率有:
22000(22kHz):无线广播。
44100(44.1kHz):CD音质。
48000(48kHz):数字电视,DVD。
96000(96kHz):蓝光,高清DVD。
192000(192kHz):蓝光,高清DVD
(2)量化,把幅度转换成离散值。每隔一定的时间间隔对波形取样一次,取样波形被量化为同一个量化值,我们一般使用二进制量化,所以量化值只有 0 和 1。在采样周期 T 内,量化产生的二进制位数称为采样的比特数或采样位数,采样位数常见的有 8 位、12 位和 16 位。比特数越多,量化的质量越高,数据量也越大。
采样与量化的关系如图

横坐标是时间轴(采样频率),纵坐标是幅度值(量化分辨率),曲线代表的是模拟信号对应的波动曲线,灰色的方格是采样量化后的所得结果。由图中可以得知,当频率越高(时间间隔越短),量化深度(量化分辨率)越大,二者的轮廓越吻合,这也说明数字化的信号能更好地保持模拟音频信号的形状,有利于保持原始声音的真实情况。
在数字音频的衡量指标中,采样频率的单位是Hz,量化深度一般用比特(bit)来度量。例如,某一音频的数字化指标是 44.1 kHz,8 个比特位。那么这里的 44.1 kHz 比较容易理解,但 8 比特位并不是说把某一单位的电压(电流)值分成 8 份,而是分成 28=256 份;同理 16 位是把纵坐标分成 216=65536 份。
(3)编码,按照一定的格式把经过采样和量化得到的离散数据记录下来。并在有效的数据中加入一些用于纠错、同步和控制的数据。在数据回放时,可以根据所记录的纠错数据判别读出的音频数据是否有错,如在一定范围内有错,可加以纠正。模拟信号经过采样和量化以后,形成一系列的离散信号——脉冲数字信号(二进制的 0 和 1)。
存储文件大小的计算:码率=采样率 x 位深度 x 声道
所以,文件码率= 44.1Khz x 16位 x 2声道 = 1411.2 Kbps;文件大小 = 码率 x 时长=1411.2 Kbps x (3 x 60 + 47 )s = 1411.2Kbps x 227s=38102.4 Kb= 37.2M,近似等于mediainfo工具显示的文件大小38.3M。
声音评价:
一、频响曲线
1、频响曲线EQ:用于描述设备在不同频率下的响应能力,即设备对不同频率声音的放大或衰减程度。
频响曲线横轴表示频率,纵轴表示增益或衰减的程度。频响曲线可以显示设备在不同频率下的相对音量水平。(相当于相机镜头的MTF曲线,即对声音的还原能力。)

说到频响曲线就需要先搞懂频响特性,输出频率与输入频率之比就是频响特性。在业界的做法是对这个比值取模然后再取对数再乘以20换算为分贝(dB),然后就成输出频谱幅值(dB)与输入频谱幅值(dB)之差了。严格来说,这个频响特性应该包括幅值特性和相位特性。通常情况下,我们不会特别关心幅值的绝对大小,而是关心相对的大小。
理想的监听系统,频率响应曲线应该较为平直。也就是说,监听系统必须在各个频率点上的表现都非常一致、稳定。声音进入系统再被回放出来,不会被改变了原样。
现实世界中,频响曲线绝对平直的理想系统是不存在的。曲线上总有些坑洼起伏——但它到底是平缓中略带“涟漪”,还是大起大落像做过山车?此时就该看看“± x dB”了。还拿Genelec 8030B来看,它频率响应的另一种表示方法是:±2 dB (58Hz – 20kHz)

例如,某个耳机的频响曲线可能在高频段上升,表示它在高音区域相对增强;在中频段保持平坦,表示中音的表现准确;在低频段下降,表示低音相对衰减
不同声音的频率范围

2、Equal Loudness Contours(等响曲线):
1933年时,美国两位在贝尔实验从事研究的科学家Harvey Fletcher与Wilden Munson在Journal of the Acoustic Society of America对人耳听觉发表一篇文章”Loudness,its definition, measurement and calculation”。他们研究发现人耳对所有频率的响度认知并不是相同的,人耳对不同频率的反应会随着音量而改变。
在低音量下,人耳对高频和低频的敏感性都会显著降低,而随着音量增大,这种差异将变小。更准确的说,在1kHz以下时,频率越低,我们就需要更大的响度才能获得与其他频率一致的听感。而超过6kHz,人耳的敏感度就会出现明显的下降。
其次,则是人耳结构对于音频的自然衰减。由于人类的耳朵结构,声音从耳朵进入耳道最终到达耳膜,这个过程中声音就已经开始产生了失真。而更为严重的问题可能是人类进化的过程中所形成的生理适应力。比如人耳对于3kHz的声音特别敏感,这主要是由于婴孩啼哭的哭声恰好就落在这一段频率上,导致在漫长的进化岁月中,人类对于这个频段的敏感程度变得越来越高。

X轴表示的是频率,Y轴表示的不同的振幅量。“Phon”(方)是一个响度单位,被感知为等于1000Hz调的分贝强度。所以可理解为一个1000Hz的正弦波在40dBSPL下播放的响度相当于40Phon。在实际应用中,我们可以把“Phon”的相对变化与“dBSPL”在响度方面的相对变化等同起来。
在同一形状或曲线上的每一个点,都会被定义为与人类平均感受能力具有相同的响度。例如,在上面的图像中,在50 dBSPL左右与200Hz交叉的蓝色线条。现在沿着这条线向左看,直到它与100Hz交叉。注意,此时相应的振幅大约是59 dBSPL。这意味着,为了让一个人感受到在200Hz的以50dBSPL播放相同的响度,必须提升9dB。
瀑布图:
我们知道声音是通过振动产生的,在没有人工干预的情况下,声音会随着振幅减弱而逐步衰减。这里就会引入到一个新的概念就是“衰减时间”。比如以前文“低频多”为例,一个衰减快的低频,会给人干净利落的感觉,而一个衰减慢的低频则会给人低频臃肿的感受。放到人声上,衰减快的中频会让人声会显得更加干净、清丽,而衰减满的中频则会让中频显得更饱满而富有氛围感。而平面的频响曲线图是无法表现出衰减速度的快慢的,因此一个加入了Z轴(时间轴)的频响曲线图就诞生了,这就是瀑布图。

在种种原因下,单纯参考频响曲线,是无法“判断器材好坏”的。即使我们经常听到,一个好的HIFI设备追求的是频响曲线的平直,不要有峰或谷就是好的曲线,但即使是一个完全平直频响的声音,被人耳接收后,也会自然的变得不平直。那面对这这样的情况,HIFI厂商是如何处理这个问题的呢?
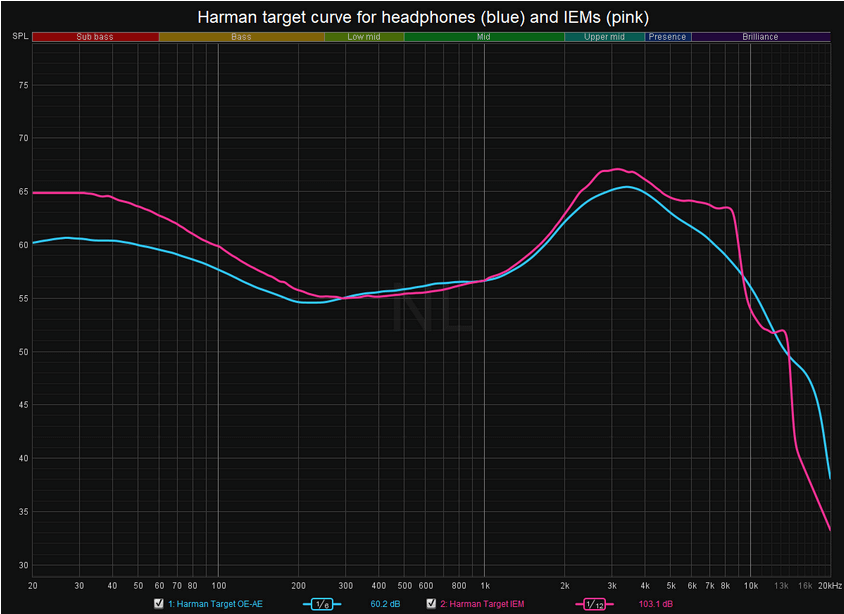
3、哈曼曲线(Harman Target Curve)
哈曼曲线是哈曼卡顿音频工程师根据听音环境、人耳结构、以及回放设备等综合因素得出的一条标准“调音”曲线,他的目的是为了让人耳最终听到的声音频响趋向于平直,也就是“听感平直”。因此,哈曼曲线是哈曼卡顿在制作回放设备时的参考标准,代表了他潜在的声音风格即风格取向。
二、其他影响因素
动态范围:动态范围的定义是最大声压级与最小声压级之间的比值。是一个相对值。
总谐波失真(+噪声):总谐波失真是一种非线性失真,它会在输入一个单频信号时,在输出中产生这个信号频率的整数倍的信号。这些额外产生的信号被称为谐波。换句话说,当你输入一个特定频率的信号时,输出中会出现该频率的倍频信号。例如,如果输入一个100 Hz的信号,输出中可能会出现100 Hz的倍频(200 Hz)、三倍频(300 Hz)、四倍频(400 Hz)等。
互调失真(+噪声):互调失真也是非线性失真的一种,它与总谐波失真的区别在于输入信号由一个单频信号变为两个单频信号。当这两个频率不同的信号经过非线性的音频设备时,输出中除了会有这两个频率的信号之外,还会有这两个信号频率的差与和的成分。这些额外产生的频率成分被称为互调产物。例如,如果输入一个100 Hz和200 Hz的信号,输出中可能会出现100 Hz和200 Hz的各自的信号,以及100 Hz和200 Hz之差(100 Hz)和和(300 Hz)的信号。
声道:立体声stereo:一般在手机厂商语境下,都是指的双声道音频。当然这也只是双声道2-channel的一种,双声道还包括double mono,直译过来就是双-单声道。即两个声道播放完全相同的声音。
声场:声场是指声音的传播和空间分布特性。在声学领域,常见的声场类别包括以下几种:
自由场(Free Field):自由场是指声音在没有任何反射和干扰的情况下传播的环境。在自由场中,声音可以自由传播,没有任何限制或反射。 反射场(Reverberant Field):反射场是指声音在存在反射和多次反射的环境中传播的情况。在反射场中,声音会在各个方向上反射、折射和散射,导致声音的延迟、混响和声音能量的分散。 室内场(Indoor Field):室内场是指声音在封闭的室内环境中传播的情况。室内场中的声音受到墙壁、天花板、地板等物体的反射和吸收影响,导致声音的衰减、混响和空间效果的改变。 户外场(Outdoor Field):户外场是指声音在开放的户外环境中传播的情况。在户外场中,声音受到大气条件、地形、建筑物等因素的影响,可能会发生衰减、扩散和传播路径的变化。 近场(Near Field):近场是指声源与接收点之间的距离相对较近的区域。在近场中,声音的特性可能与远离声源的远场有所不同,包括声压级、频率响应和声场均匀性等方面的差异。
参考:
https://zhuanlan.zhihu.com/p/639479386
https://www.rainlain.com/index.php/2021/03/13/927/
音频的3A算法
AEC:Acoustic Echo Cancellation 回声消除
AGC:Automatic Gain Control 自动增益控制
ANS:Adaptive Noise Suppression 噪声抑制






